
{kind=link}
Microsoft has been working on a new tool called VALL-E that can clone anyone’s voice with a second audio sample of that person. The tool uses Artificial Intelligence to create a natural-sounding voice.
Text-to-speech (TTS) technology has been around for some time, and Artificial Intelligence (AI) is changing how it works. AI is being used to improve text-to-speech capabilities.
I am assuming that this AI-based technology VALL-E, will complement Microsoft’s existing Speech Studio which has a dozen realistic human-like voices.
Microsoft is investing heavily in AI
VALL-E sounds similar to DALL-E, an AI product from OpenAI launched in 2021, where Microsoft has invested huge amounts of money. DALL-E is now in its second version called DALL-E 2, launched in 2022, which creates images from text prompts. The Images are quite realistic.
For example, when the prompt given to create Avacado Chair, here is one of the images it created.

Open AI launched ChatGPT in 2022, which attracted over 1 million users in just 5 days of its launch. It’s currently in Beta version so it is free to use
Microsoft made a $1 Billion investment in OpenAI in 2019. And it will be investing another $10 Billion in the company.
Here’s how VALL-E works
All though it has not been released to the general public yet Microsoft has showcased how VALL-E works and has put up some samples on a demo page on GitHub.
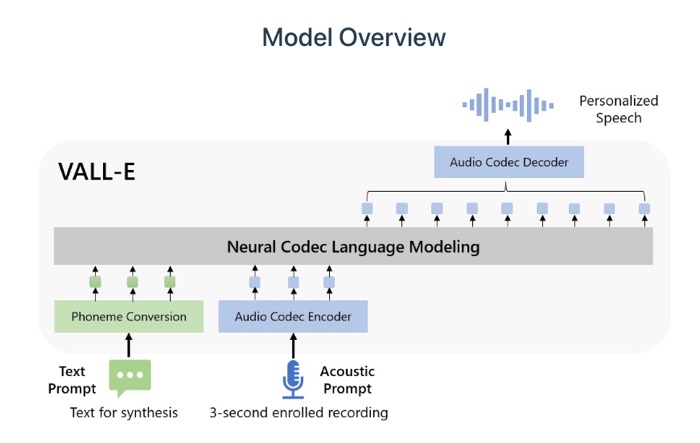
The page has many – second sample voices of people and VALL-E converting text in the same voice. In the demo, it states the AI is also capable of depecting the acoustics of the orginal sound. If it’s a telephonic voice sample, the text any be convered the same telephonic type voice.
It can also depdict the emotion and put that one the voice created using Text-to-Speech.
The Potential Risk of Voice Cloaning
Like every other technology, this one also has its pros and cons. I can see tools and services building on top of these technologies. For Example, maybe you have a sample voice of your deceased loved one. You can still talk to them and they will reply to you.
But there is also DeepFakes, which can be really nasty political tool as we have already seen several of them. With tools like these becoming more accessible, we will be seen more such videos.
VALL-E, is not the first product that clones a human voice. There already tools available, but the difference is, the amount of sample data they require.
There is a tool called Discript, which can also clone your voice. It offers a text based editing for Podcasts, where you can use clonsed voice to easily dub words between your orginal Podcast.
But it requires you to authorize it for closing your voice and you have to speak for a few minutes, then it will upload the data to its servers, and the process takes sometime before you are able to use the cloned voice.
With VALL-E creating and cloning voice with samples as short as 3 seconds, things are going to be a little more scary. Microsoft nose that, and they have included ethics statement on the demo page itself with says,
Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker.
We conducted the experiments under the assumption that the user agree to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.